.png)

-XbQiWTFJeLcIomNXDtvISOaGYYVWIEKo.png)
AI 也要算‘字数’?一分钟搞懂 Token 计费奥秘!
一、什么是 Token?
直观理解:Token 就是 AI 模型“阅读”文字的最小单位,可以类比成“单词碎片”或“字数”拆分。
拆分示例:
“今天天气真好” → 可能被拆成
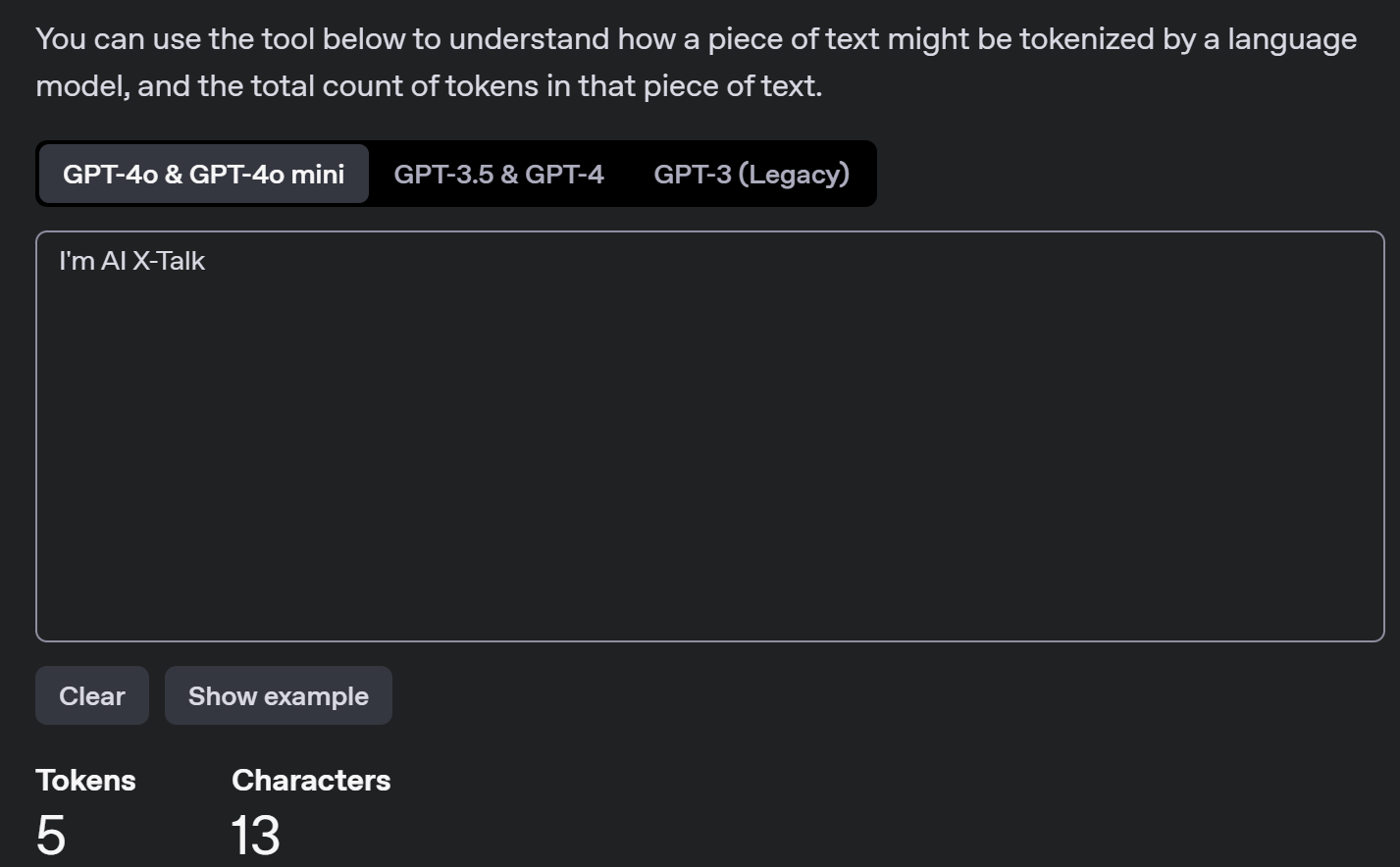
["今","天天","气","真","好"]共 5 个 Token。Token 与字符的经验比:一般 1 Token ≈ 4 个英文字符,或约 0.75 个汉字
二、Token 为什么要计费?
计费单位:所有主流大模型(如 GPT-3.5、GPT-4、Claude、Gemini、Deepseek等)都会按输入(prompt)和输出(completion)Token 总数收费。
为何如此:Token 数直接关联到模型的计算量和资源消耗,Token 越多,花费越高。
三、官方计量与计费工具大全
OpenAI Tokenizer 在线演示
功能:实时展示输入文本如何被分割成 Token,并计算总数。
OpenAI API 定价页面
各模型最新费率、示例计算器都在这里。

第三方 Token 计算器
例如:https://token-calculator.net/(支持 OpenAI、Anthropic、Google 等多家厂商)。

也可用社区工具如 JTokkit(Java)、tiktoken(Python)在本地项目中统计。
四、主流模型 Token 计价对比
计算示例:
一次对话:输入 500 Token,输出 1,000 Token;若用 GPT-4 Turbo,费用 = 0.5×$0.01 + 1×$0.03 = $0.035
五、如何查看自己用了多少 Token?
ChatGPT 界面(付费用户可见):对话框右下角自动显示本次 Token 用量。
API 返回值:调用 OpenAI 接口时,响应中含
usage字段,里头有prompt_tokens、completion_tokens、total_tokens。在线/离线工具:上述 Tokenizer 与第三方计算器,都能一键粘贴文本或日志统计。
六、省钱妙招:有效控制 Token 消耗
精简 Prompt:去掉多余背景,指令精准。
限制输出长度:如加上
“请最多回答 50 字”。分级调用模型:简单任务(天气、计算)用 GPT-3.5,写作、翻译等高质量文本再用 GPT-4。
上下文复用:不重复传输历史记录,只保留必要摘要。
批量请求:合并多个小请求为一次大请求,减少重复模型加载开销。
七、未来展望:长上下文与更高性价比模型
长上下文趋势:128K、甚至 1M Token 正在研发中,长文档处理更方便,但费用也会随之上升。
新降本模型:Mini 系列、开源 LLM(如 LLaMA、Mistral)持续下调使用成本,企业可混合部署。
企业成本控制:可引入 Token 上限告警、定期报表分析、调用优先级管理等手段。
✏️ 小结:
了解 Token、学会用官方和第三方工具精准统计,并结合模型特性选型,就能在保证 AI 体验的同时,有效管控成本,避免“你以为免费的背后其实早就偷偷扣了你的钱”!